茉莉炒股从-0-到-1
0 序言
本文将描述微信小程序“茉莉炒股”从 0到 1,从产品原型到设计到开发到落地的实现过程,记录项目实施的各个环节及重要细节。同时服务端源码,爬虫源码,小程序源码也在 github 上同步开放,供参考。
1 项目规划
凡事预则立,不预则废。
列出完成该项目将涉及的所有环节,做到有的放矢。
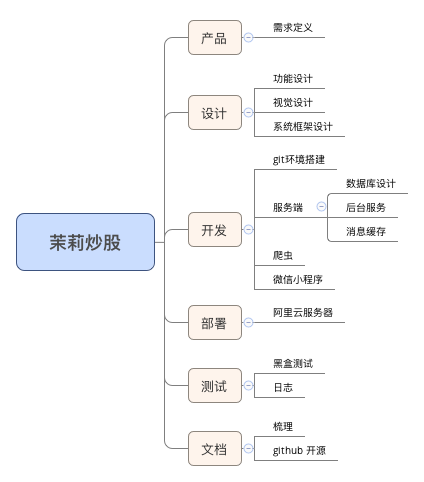
明确实施步骤,制定项目 Roadmap:

并评估各个模块需要完成时间,控制项目进度。
2 产品需求定义
该产品用于模拟股票交易,提供港股市场和美股市场个人觉得值得关注的个股列表,股票数据从券商网站爬取,在股票交易时间段内爬虫会每 10分钟爬取刷新一次,同时提供虚拟资金作为模拟交易,详细需求如下:
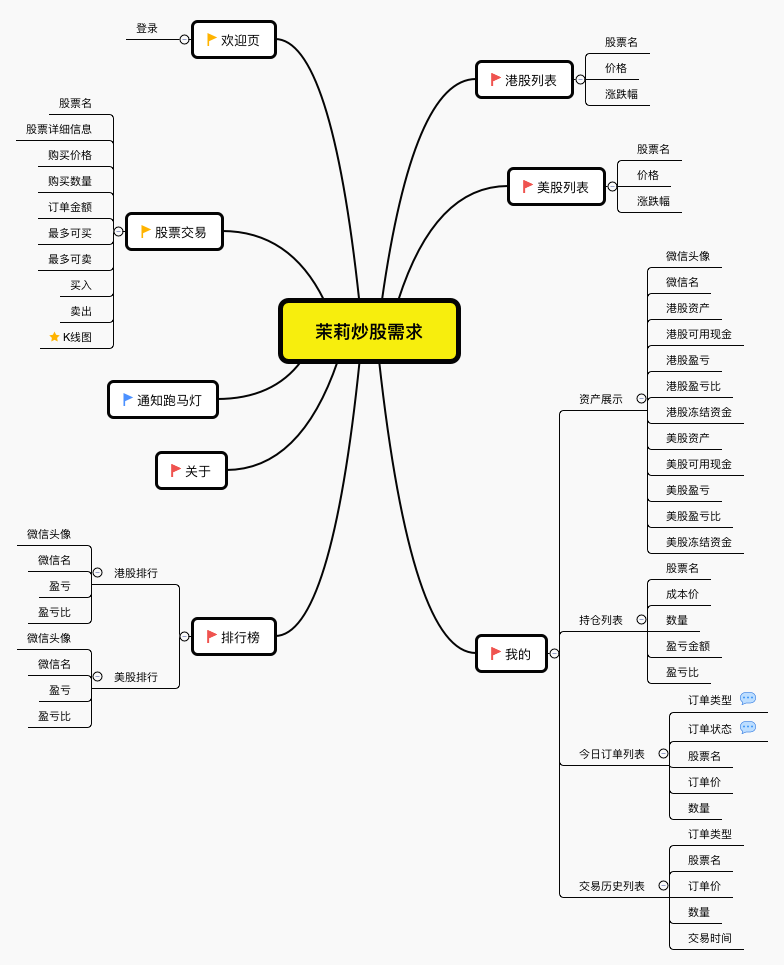
3 产品设计
根据产品定义,明确所有需求点共分 5个一级页面,即 5个 Tab 页:
- 港股列表
- 美股列表
- 我的详情页
- 收益排行榜
- 关于说明页
两个二级页面:
- 欢迎页
- 股票交易页面
一个功能点:
- 消息通知跑马灯
及未列出的服务端报错页面。
4 系统架构
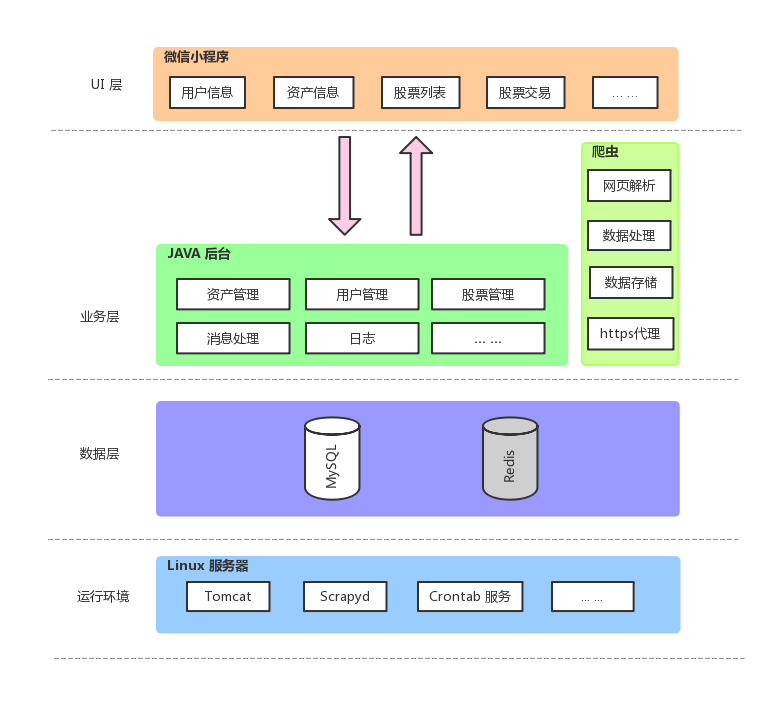
针对产品设计的形态,将该应用的系统结构划分为 5大模块,各模块之间彼此协作完成产品功能,
- 微信小程序端
- 后台 Server 端
- MySQL 数据库
- Redis 缓存
- 爬虫
应用各模块间交互示意如图:
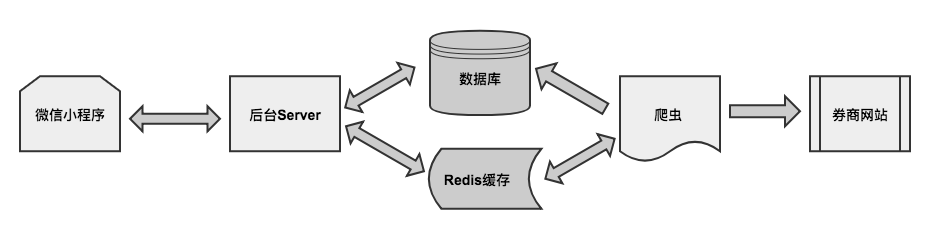
该系统运行是由爬虫模块驱动,爬虫按照规则定时启动上券商网站爬取股票数据,主动更新数据库,同时从 Redis 缓存获取用户股票订单信息,根据爬取到的股价数据判断此股票订单交易是否成功,如成功,则通过 Redis 发布消息给后台 Server。
后台 Server 负责维护用户信息和资产数据的管理,处理微信小程序端请求。例如收到股票交易请求,则将股票订单信息存放进 Redis 缓存,并监听爬虫端发布的消息,如股票交易成功,更新订单状态,同时更新用户相关资产数据。
整个应用的系统架构如图:
5 环境准备
实现产品的技术选择有很多,根据自己熟悉的来,我选择的技术栈是 SpringBoot + MyBatis 作服务后台;Tomcat Web 容器;MySQL 数据库;Redis 作缓存;Scrapy 爬虫框架;微信小程序平台。
这里给两个建议,
1) 使用 Git 管理代码。
即使只有一个人单干不需要和其他人协同。通过 Git 可以很方便的记录代码变更历史,同时作为代码备份,还可创建分支自由切换开发环境毫无负担。
2) 搭建 MVP。
MVP 即最小可执行产品,按照这个思路先迅速搭建出可运行的最基本的应用结构,然后在此结构基础上增添功能,这样针对每个功能点后台服务端和微信小程序端可以有效的配合开发,快速拿到验证结果,持续完善和迭代。
6 通信协议
当前版本协议采用传统风格(下个版本再改成 RESTful 风格),以进入“我的” Tab 页的第一个请求为例
客户端请求
GET /okistock/my/main
参数
openid=oa4Co5b7R_Sn0fSAbkqU-xu7jXZg
服务端返回
{
"code": 0,
"msg": "Success",
"data": {
"user": {
"openid": "oa4Co5b7R_Sn0fSAbkqU-xu7jXZg",
"nickName": "0ki",
"avatarUrl": "https://wx.qlogo.cn/mmopen/vi_32/DYAIOgq83eqhXbPkl4XXh0athBbxgqT2ILpTbUdjTc78x9KNfborMF6o0nTicdCyHxG5rzRRs6mJKBkN6H40tHA/132",
"hkAssets": "162742.00",
"hkRestDollar": "31688.00",
"hkProfitAmount": "-37258.00",
"hkProfitPercent": "-18.63%",
"hkFrozenCapital": "80180.00",
"usAssets": "20000.00",
"usRestDollar": "20000.00",
"usProfitAmount": "0.00",
"usProfitPercent": "0.00%",
"usFrozenCapital": "0.00",
"hkRise": false,
"usRise": false
},
"holderList": [
{
"stockId": 1,
"stockName": "腾讯控股",
"stockScope": "hk",
"costPrice": "377.40",
"stockNums": 300,
"profitAmount": "-28620.00",
"profitPercent": "-25.28%",
"rise": false
},
{
"stockId": 2,
"stockName": "吉利汽车",
"stockScope": "hk",
"costPrice": "47.10",
"stockNums": 1300,
"profitAmount": "-43004.00",
"profitPercent": "-70.23%",
"rise": false
}
],
"notification": {
"title": "通知",
"message": "代码开源了,请在“关于”里面查看介绍"
},
"tradingFlag": {
"hkTrading": true,
"usTrading": false
}
}
}
7 数据存储
选择主流的 MySQL + Redis,用 Druid 作数据库连接池。
根据业务特点建5个表,分别是:
oki_user :用户表,保存用户信息及港美股资产信息
oki_stock :股票表,保存股票的股价等详细信息
order_info :订单信息表,保存用户交易股票订单的所有信息,及订单状态
stock_holder :用户股票持仓表,保存用户持有股票及涨跌数据等信息
notification :信息通知表,存储系统通知用户的消息
以 order_info 建表为例
CREATE TABLE order_info(
order_id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
openid VARCHAR(36) NOT NULL,
stock_id INT(2) NOT NULL,
stock_name VARCHAR(20) NOT NULL,
stock_scope CHAR(2) NOT NULL,
quote_price VARCHAR(8) NOT NULL,
quote_nums INT(8) NOT NULL,
order_type CHAR(1) NOT NULL,
order_status CHAR(1) NOT NULL,
commit_time DATETIME NOT NULL,
exchange_price DECIMAL(10,2),
exchange_time DATETIME,
gmt_create DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
gmt_modified DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
因为查询订单主要是以 openid 为条件,所以为 openid 字段建立索引。
Redis 作缓存服务器及 JAVA 服务端与 Python 爬虫间交互的消息服务器。
8 服务端
选择主流的 SpringBoot + MyBatis 实现。 这里通过分析一个典型的 “股票买入成功” 的应用场景,来探究整个后台的交互工作流程。
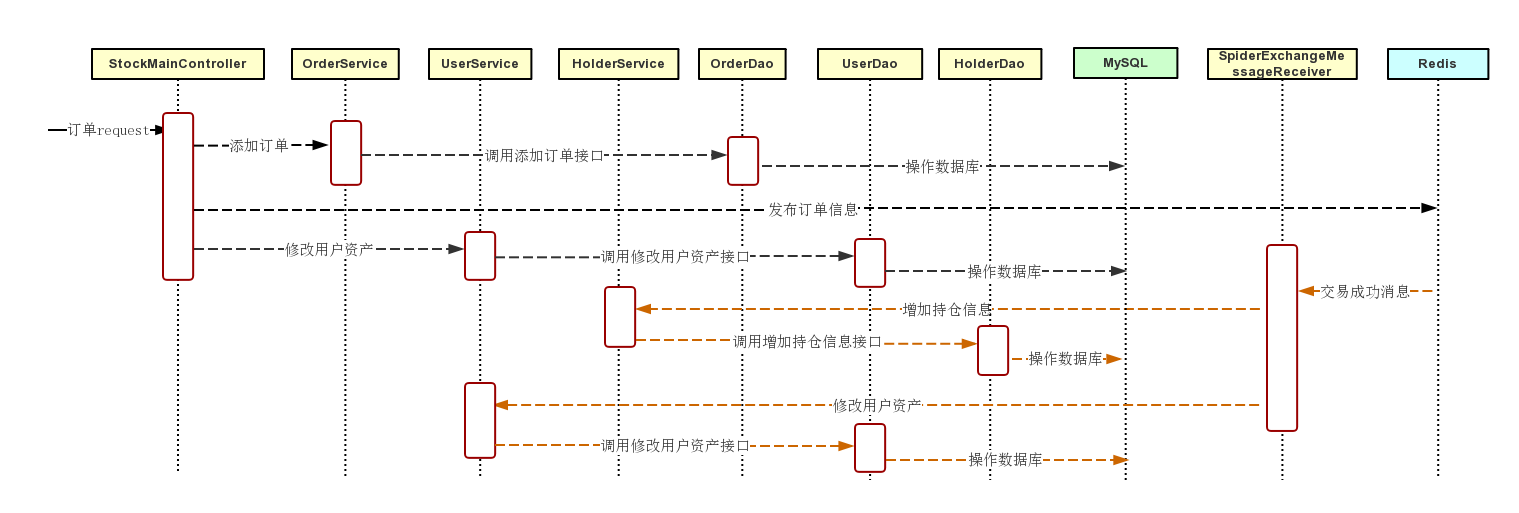
小程序端发 https 请求,由对应的 Controller 接收,调用相应的 Service 做业务逻辑处理,具体的数据库操作由具体 Dao 负责,所有业务请求响应的处理流程都遵循此链条。
还有一端是监听 Redis,由具体的 Handler 注册配置 topic,当收到爬虫端发布的消息,也调用对应 Service 做业务逻辑处理,再交给 Dao 层负责具体的数据库操作。
9 小程序
小程序端未采用任何第三方框架,使用小程序提供的原生组件和 API 开发。
下图是整个小程序端的代码框架
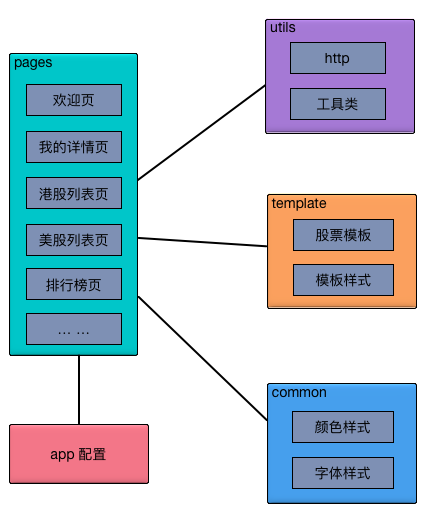
app.json 和 app.js 提供了小程序运行的基本配置信息和全局变量,pages 目录下包括所有的可见页面,通过自己封装好的 http 工具类请求业务数据,将可复用的布局和样式封装成模板,一些常用颜色和字体也统一规范。
首次打开该小程序将检查本地是否有存储 openid,如果检查到没有则说明是第一次运行,将向微信服务端请求用户授权,获取用户 openid,用户昵称及头像。
10 爬虫
采用 Python 的 Scrapy 作为爬虫代码的主框架。Scrapy 对网页解析,数据提取,并发管理,数据存储等方面都做了良好的封装,扩展和配置相关组件就能满足需要。下面重点介绍三个方面,
1)目标网站分析
打开目标券商网站,发现不需要登录就能展现股票相关信息,省去了模拟登录和识别验证码,相对静态,也不用 JavaScript 引擎渲染。
用 Chrome 分析该网站的网络请求和响应,查看 Headers
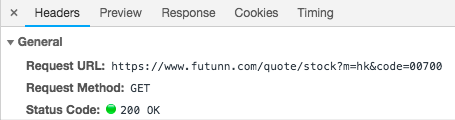
查看请求参数,m 取值是股票代表所属市场,code 取值是股票代号

这个 HTTP GET 请求就可以拿到目标股票页面,但还需要拿到股票交易的报价,继续分析发现

这个请求能将交易时段内该股票每一分钟的报价数据返回,但需要带两个参数 security_id 和 _ , security_id 是该目标页面一条隐藏域的值,_ 则是当前时间戳。好了,爬虫构建这两条 GET 请求就可以基本满足对股票数据的需求了。
2)数据处理
主要是配置使用 Scrapy 的组件,构造自定义的 ItemLoader 提取数据,构造自定义的 Item 封装数据,构造自定义的 Item Pipeline 连接 MySQL 保存数据。
考虑到最终数据的流向都会经过 Item Pipeline,我在 Item Pipeline 处理从 Redis 缓存获取的用户提交的股票交易订单,根据拿到的股票每分钟报价去判断该笔交易是否成功,如成功,则会向 Redis 发消息通知 JAVA 后台处理。
3)IP 代理池
为了避免在爬取过程中 IP 被 bang,使用代理就非常有必要,虽然国内有不少网站提供免费代理 IP 地址,但是可用率很低,因为吝啬不考虑使用收费的,因此需要对大量的免费代理做过滤,验证其是否可用。
验证流程如下:
- 构造请求上免费代理网站获取 IP 列表,这里使用 BeautifulSoup 去解析 IP 列表页面。
- 获取到解析的 IP 作为 urllib request 的请求参数上 http://httpbin.org/ip 做验证。
- 判断响应码是否为200,如为200,还需判断该 IP 是否会暴露本机 IP,如果会暴露也将舍去。
经过这些步骤后就有了可用率较高的代理,爬虫在每次运行前会先去构造最新的代理池,从代理池里面随机挑选 IP 再去目标网站爬取。如果代理池可用 IP 数量少于5个了,又将重新去构造新的代理 IP 池。
11 上线部署
我在阿里云购买了轻量应用服务器和域名,将服务器系统置为 CentOS,安装和配置服务端需要的运行环境 JDK 1.8,Tomcat 8,MySQL 5.7,Redis,以及爬虫运行环境 Python 3.6.4 和 Scrapyd。
要记录一个坑。Python 3.6.6 这个版本安装 sqlite 最新包会报 “No module named '_sqlite3'” 的错误,google 出来的解决方案都不可行,后来将 Python 版本降级才跳坑。
使用 Scrapyd 可以很方便的管理爬虫,了解爬虫运行状况。编写调用脚本同时配合 Crontab 做定时任务,下面给出针对港股和美股真实交易时间的定时规则
29 9 * * 1-5 sh /root/spider/hk_start.sh
30,40,50 9 * * 1-5 sh /root/spider/hk_crawl.sh
*/10 10-11 * * 1-5 sh /root/spider/hk_crawl.sh
0 12 * * 1-5 sh /root/spider/hk_crawl_no.sh
*/10 13-15 * * 1-5 sh /root/spider/hk_crawl.sh
0 16 * * 1-5 sh /root/spider/hk_crawl_no.sh
5 16 * * 1-5 sh /root/spider/hk_finish.sh
29 21 * * 1-5 sh /root/spider/us_start.sh
30,40,50 21 * * 1-5 sh /root/spider/us_crawl.sh
*/10 22-23 * * 1-5 sh /root/spider/us_crawl.sh
*/10 0-3 * * 2-6 sh /root/spider/us_crawl.sh
0 4 * * 2-6 sh /root/spider/us_crawl_no.sh
5 4 * * 2-6 sh /root/spider/us_finish.sh
会在港股美股每天开市前一分钟发消息通知后台当天交易开始,然后开市后每隔10分钟运行一次爬虫,在每天休市后的第5分钟通知后台当天交易结束,将 Redis 里面未完成的订单数据清除,并更新数据库该订单为失败状态。
12 测试调优
因为吝啬所以购买的服务器很乞丐,1核CPU 2G内存 1Mbps网络的配置,压测并发先略过吧。。。
针对爬虫,虽然有了经过验证的代理池,但是去目标网站访问依然会有很多代理无效,导致爬虫请求超时影响爬取效率。所以又做了进一步优化,一旦发现某代理 IP 正常好用,就放进一个 good_proxies 列表存起来,后面的爬虫拿代理优先从这个 good_proxies 列表获取。当 good_proxies 不为空时,爬取效率大大提高。
13 补充
- 源码里面我把服务器地址,数据库用户名、密码,小程序 appId、appSecret 等敏感字段故意隐去了。
- 小程序上线发布必须要用备案的域名,备案的域名!
- 有个策略上的优化,港股美股每天闭市的最后一次数据爬取,不走代理而是用当前IP 直连,但必须设置爬虫 DOWNLOAD_DELAY 属性5秒,尽可能让 IP 不被 BANG,确保当天股票数据和订单交易不会遗漏,保证数据最终一致性。
- 本来产品计划小程序的股票交易页面有 K 线图展示,这个有点费劲,计划放在小程序下个版本,如果有的话。。
- 爬虫的代理还是没有达到我最理想的状态。Scrapy 设计的每个 Request 是单独的线程做并发,我希望当 good_proxies 一旦有值就立即通知其他线程的 Request 取消而采用 good_proxies 里面的代理 IP 请求重发,可以进一步减少重试的时间。Scrapy 线程管理用的 Twisted,需要看源码再研究下。
- 好了,谢谢来访,如果有什么想和作者交流可以发邮件 81522491@qq.com
相关文章
- 硅谷互联网公司的开发流程
开发流程包括这么几个阶段: OKR 的设立; 主项目及其子项目的确立; 每个子项目的生命周期; 主项目的生命周期; 收尾、维护、复盘。 第一点,OKR 的设立 所有项目的起始,都应该从 Ro
- RESTful-表述性状态转移风格
REST英文全拼:Representational State Transfer 面向资源编程 资源指的就是一类数据 产品表->就是产品资源 最重要的是如何表示一个资源 地址即
- 稳定性思考
产品功能线 0-1: 当系统从无到有的时候,首要考虑的是研发效率,功能快速迭代,满足快速增长的业务需求 1-10 系统已经搭建起来,此时考虑的是系统的稳定性。 可用性:1.隔离:区分出核心和非核心功能
- Supervisor守护队列发邮件
安装 CentOS: yum -y install supervisor Debien/Ubuntu适用:apt-get install supervisor 配置 修改主配置文件:vim /et
- 安装libsodium,让服务器支持chacha20等加密方式
用chacha20加密方式需要安装libsodium 注意:libsodium从1.0.15开始就废弃了aes-128-ctr yum install wget m2crypto git libsod
随机推荐
- 硅谷互联网公司的开发流程
开发流程包括这么几个阶段: OKR 的设立; 主项目及其子项目的确立; 每个子项目的生命周期; 主项目的生命周期; 收尾、维护、复盘。 第一点,OKR 的设立 所有项目的起始,都应该从 Ro
- RESTful-表述性状态转移风格
REST英文全拼:Representational State Transfer 面向资源编程 资源指的就是一类数据 产品表->就是产品资源 最重要的是如何表示一个资源 地址即
- 稳定性思考
产品功能线 0-1: 当系统从无到有的时候,首要考虑的是研发效率,功能快速迭代,满足快速增长的业务需求 1-10 系统已经搭建起来,此时考虑的是系统的稳定性。 可用性:1.隔离:区分出核心和非核心功能
- Supervisor守护队列发邮件
安装 CentOS: yum -y install supervisor Debien/Ubuntu适用:apt-get install supervisor 配置 修改主配置文件:vim /et
- 安装libsodium,让服务器支持chacha20等加密方式
用chacha20加密方式需要安装libsodium 注意:libsodium从1.0.15开始就废弃了aes-128-ctr yum install wget m2crypto git libsod