Spark消费Apache-kafka代码示例
当前从kafka 0.10.0版本以后对安全访问验证做了限制,支持SSL和SASL认证两种模式。所以为了测试对开源kafka的支持,我们需要重新部署kafka和zookeeper。
注意事项
kafka的server和源码中访问的kafka client的包必须一致,否则会出现不可预知的数据消费问题。
代码讲解
package demo
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* spark 与 kafka 集成demo
*/
object SparkAndKafkaDemo {
/**
* Main 程序的主方法
* @param args
*/
def main(args: Array[String]): Unit = {
/**定义程序运行的名称**/
val appName = "sparkKafkaDemo";
/**消费组**/
val groupId = "test_group"
/**kafka的地址**/
val brokers = "tbds-xxxx:9092";
/**初始化spark conf的信息,采用本地运行模式**/
val sparkConf = new SparkConf().setAppName(appName);
val sc = new StreamingContext(sparkConf,Seconds(5));
//定义topic
var topics = Array("test01").toSet;
//定义kafka的参数
val kafkaParams = collection.Map[String, Object](
"bootstrap.servers" -> brokers,
"key.serializer" -> classOf[org.apache.kafka.common.serialization.StringSerializer],
"value.serializer" -> classOf[org.apache.kafka.common.serialization.StringSerializer],
"key.deserializer" -> classOf[org.apache.kafka.common.serialization.StringDeserializer],
"value.deserializer" -> classOf[org.apache.kafka.common.serialization.StringDeserializer],
"group.id" -> groupId,
//消费的位置,从最初,还是最新开始消费
"auto.offset.reset" -> "latest",
//是否自动提交,如果不需要就手动提交,当发送或者消费成功以后。
"enable.auto.commit" -> (true: java.lang.Boolean)
)
//定义消费者,忽略offset的设置了哈
var consumerStrategy = ConsumerStrategies.Subscribe[String,String](topics,kafkaParams);
//通过kafaUtils来进行数据的读取
val lines = KafkaUtils.createDirectStream(sc,LocationStrategies.PreferConsistent,consumerStrategy)
//读取的数据进行转换成单词,根据空格进行分割,然后在统计技术
lines.foreachRDD(r => {
r.foreach(x =>{
print("=================================================="+x.value())
})
})
//通过sparkcontenxt进行程序的启动
sc.start()
//程序如果结束以后关闭,程序结束
sc.awaitTermination()
}
}
编译和打包
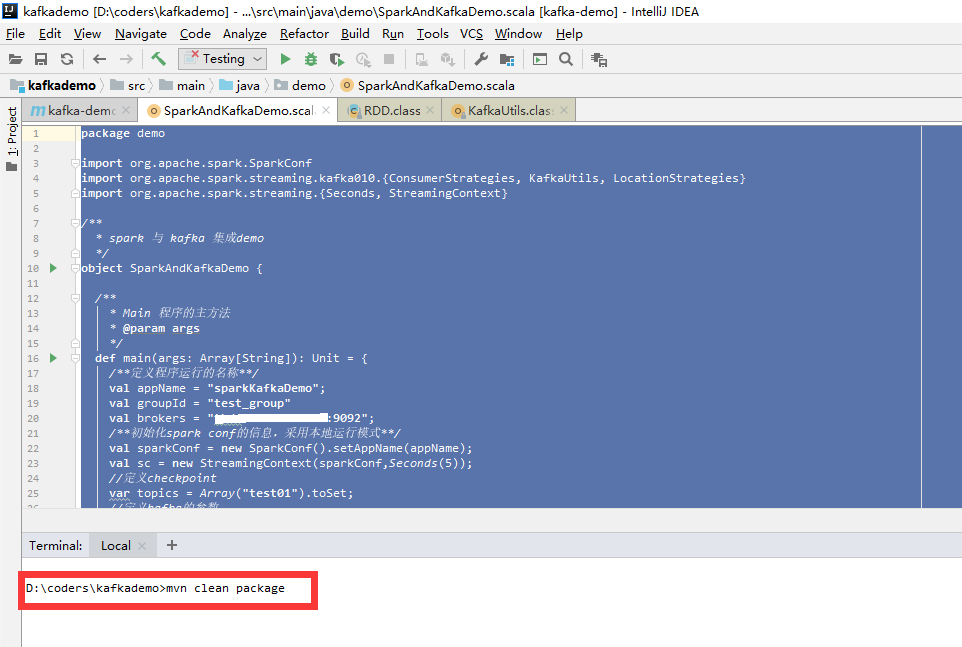
发布程序
登录服务器,然后切换到spark的bin目录,然后提交jar

发送测试数据
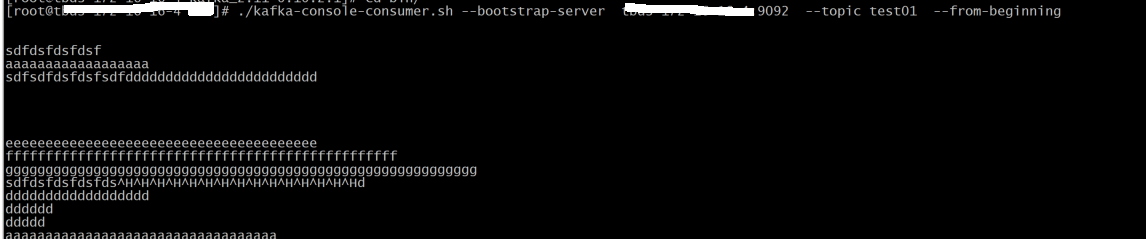
检查是否已经完成消费

查看yarn的日志,数据是否打印
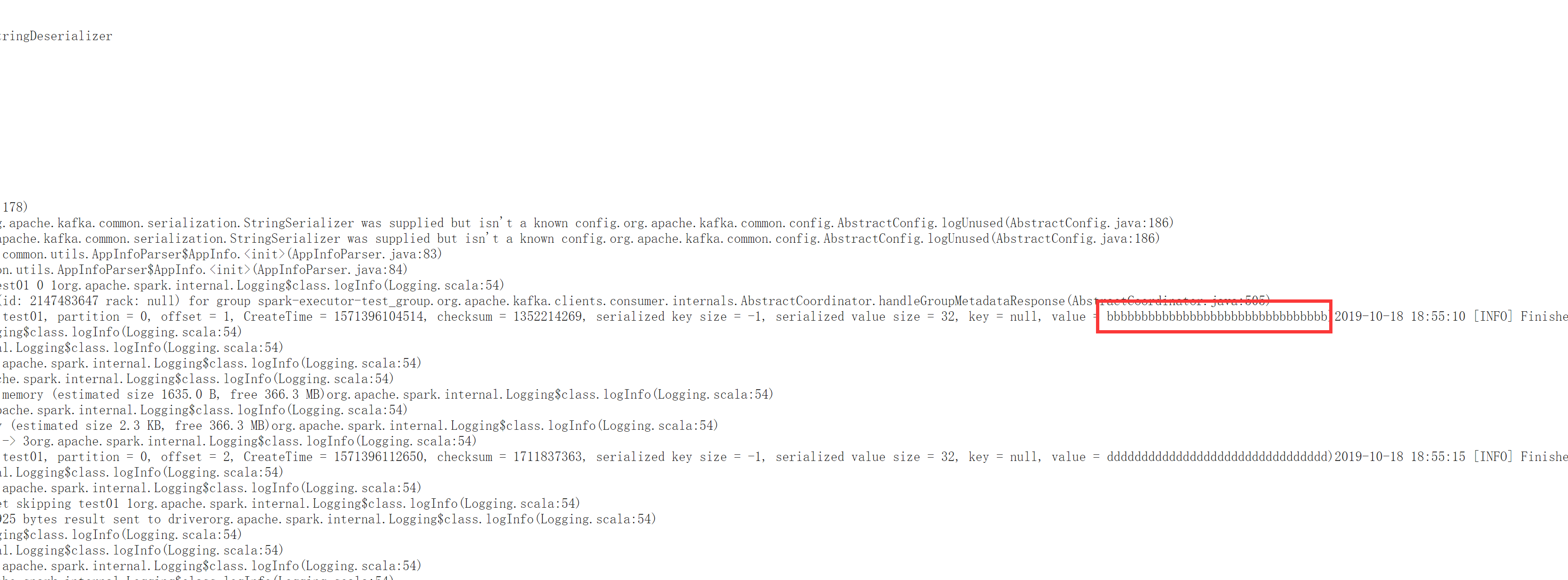
代码
相关文章
- 基于-SLF4J-MDC-机制的日志链路追踪配置属性
ums: # ================ 基于 SLF4J MDC 机制的日志链路追踪配置属性 ================ mdc: # 是否支持基于 SLF4J MDC
- ajax-跨域访问
ajax 跨域访问 <!DOCTYPE html> <html xmlns:th="http://www.w3.org/1999/xhtml"> <head>
- 给第三方登录时用的数据库表-user_connection-与-auth_token-添加-redis-cache
spring: # 设置缓存为 Redis cache: type: redis # redis redis: host: 192.168.88.88 port
- Java动态代理
Jdk动态代理 通过InvocationHandler和Proxy针对实现了接口的类进行动态代理,即必须有相应的接口 应用 public class TestProxy { public
- Java读取classpath中的文件
public void init() { try { //URL url = Thread.currentThread().getContextClassLo
随机推荐
- 基于-SLF4J-MDC-机制的日志链路追踪配置属性
ums: # ================ 基于 SLF4J MDC 机制的日志链路追踪配置属性 ================ mdc: # 是否支持基于 SLF4J MDC
- ajax-跨域访问
ajax 跨域访问 <!DOCTYPE html> <html xmlns:th="http://www.w3.org/1999/xhtml"> <head>
- 给第三方登录时用的数据库表-user_connection-与-auth_token-添加-redis-cache
spring: # 设置缓存为 Redis cache: type: redis # redis redis: host: 192.168.88.88 port
- Java动态代理
Jdk动态代理 通过InvocationHandler和Proxy针对实现了接口的类进行动态代理,即必须有相应的接口 应用 public class TestProxy { public
- Java读取classpath中的文件
public void init() { try { //URL url = Thread.currentThread().getContextClassLo