Zookeeper-请求处理器链
Leader
主要工作
- 事务请求的唯一调度者,保证集群事务处理的顺序性
- 集群内部各服务器的调度者
请求处理器链
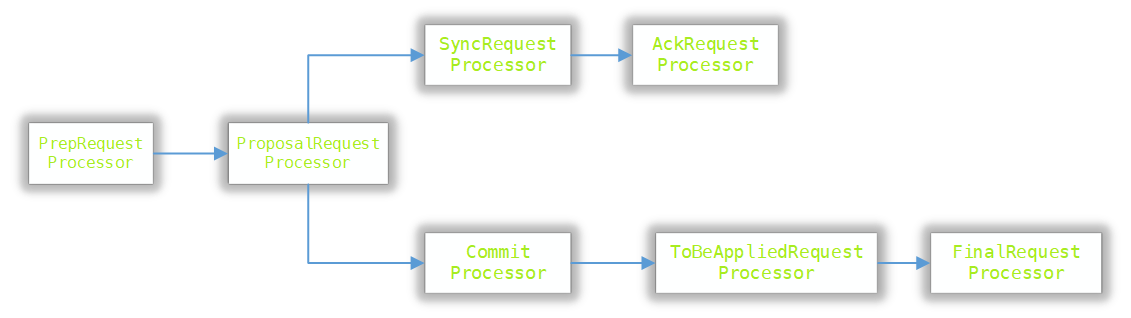
PrepRequestProcessor 是Leader服务器的请求预处理器,也是Leader服务器的第一个处理器。PrepRequestProcessor能够识别出当前客户端请求是否是事务请求。 对于事务请求,会对其进行一系列预处理,如创建请求头、事务体、会话检查等
ProposalRequestProcessor Leader服务器的事务投票处理器,也是Leader服务器事务处理流程的发起者。对于非事务,直接将请求流转到CommitProcessor处理器。 对于事务请求,除了将请求流转到CommitProcessor处理器外,还会根据请求类型创建对应的Proposal提议,并发送给所有Follower服务器来发起 一次集群投票。同时,还会将其交给SyncRequestProcessor处理器进行事务日志记录。
public void processRequest(Request request) throws RequestProcessorException {
if(request instanceof LearnerSyncRequest){
zks.getLeader().processSync((LearnerSyncRequest)request);
} else {
// 提交给下一个处理器:CommitProcessor
nextProcessor.processRequest(request);
// 事务请求处理器的额外处理逻辑
if (request.hdr != null) {
// We need to sync and get consensus on any transactions
try {
// Leader 服务器发起一个PROPOSAL提议
zks.getLeader().propose(request);
} catch (XidRolloverException e) {
throw new RequestProcessorException(e.getMessage(), e);
}
// SyncRequestProcessor处理器进行事务日志记录
syncProcessor.processRequest(request);
}
}
}
Leader 服务器发起一个PROPOSAL提议
public Proposal propose(Request request) throws XidRolloverException {
/**
* Address the rollover issue. All lower 32bits set indicate a new leader
* election. Force a re-election instead. See ZOOKEEPER-1277
*/
if ((request.zxid & 0xffffffffL) == 0xffffffffL) {
String msg =
"zxid lower 32 bits have rolled over, forcing re-election, and therefore new epoch start";
shutdown(msg);
throw new XidRolloverException(msg);
}
ByteArrayOutputStream baos = new ByteArrayOutputStream();
BinaryOutputArchive boa = BinaryOutputArchive.getArchive(baos);
try {
request.hdr.serialize(boa, "hdr");
if (request.txn != null) {
request.txn.serialize(boa, "txn");
}
baos.close();
} catch (IOException e) {
LOG.warn("This really should be impossible", e);
}
QuorumPacket pp = new QuorumPacket(Leader.PROPOSAL, request.zxid,
baos.toByteArray(), null);
Proposal p = new Proposal();
p.packet = pp;
p.request = request;
synchronized (this) {
if (LOG.isDebugEnabled()) {
LOG.debug("Proposing:: " + request);
}
lastProposed = p.packet.getZxid();
outstandingProposals.put(lastProposed, p);
// 发送提议
sendPacket(pp);
}
return p;
}
SyncRequestProcessor 将事务请求记录到事务日志文件中,同时还会触发Zookeeper进行数据快照。 toFlush以及flush时机 toFlush队列可用于存储请求,可能是读也可能是写。
刷入磁盘的时机:
- 如果没有请求的时候(即较空闲的时候)
- 如果一直繁忙,则toFlush队列到达了一定数量(1000),就会批量同步
数据快照 每进行一次事务日志记录之后,ZooKeeper都会检测当前是否需要进行数据快照。 Zookeeper采取“过半随机”策略,避免ZooKeeper集群中所有机器在同一时刻进行数据快照。 logCount > (snapCount / 2 + randRoll) logCount代表了当前已经记录的事务日志数量,randRoll为1 ~ snapCount/2之间的随机数,因此上面的条件就相当于:如果我们配置的snapCount为100000,那么ZooKeeper会在50000 ~ 100000次事务日志记录后进行一次数据快照。
事务日志文件切换 当满足上述条件时,ZooKeeper就要开始进行数据快照了。首先是进行事务日志文件的切换。所谓的事务日志文件切换时指当前的事务日志已经“写满”,需要重新创建一个新的事务日志。即每当进行一次数据快照,重新创建一个事务日志文件。
public void run() {
try {
int logCount = 0;
setRandRoll(r.nextInt(snapCount/2));
while (true) {
Request si = null;
if (toFlush.isEmpty()) {
// 阻塞出队
si = queuedRequests.take();
} else {
// 返回指定值,如果队列没有请求,返回null
si = queuedRequests.poll();
// 当队列中没有请求的时候,进行事务日志磁盘的刷入操作
if (si == null) {
flush(toFlush);
continue;
}
}
if (si == requestOfDeath) {
break;
}
if (si != null) {
// track the number of records written to the log
// 请求添加至日志文件,只有事务性请求才会返回true
if (zks.getZKDatabase().append(si)) {
// 当前已经记录的事务日志数量 + 1
logCount++;
// 采取“随机过半”策略进行快照,避免所有服务器在同一时刻进行数据快照
if (logCount > (snapCount / 2 + randRoll)) {
// 重新设置下一次的随机数
setRandRoll(r.nextInt(snapCount/2));
// 切换事务日志文件
zks.getZKDatabase().rollLog();
// take a snapshot
// 正在进行快照
if (snapInProcess != null && snapInProcess.isAlive()) {
LOG.warn("Too busy to snap, skipping");
} else {
// 新创建并启动一个线程进行快照,将sessions和datatree保存至snapshot文件
snapInProcess = new ZooKeeperThread("Snapshot Thread") {
public void run() {
try {
zks.takeSnapshot();
} catch(Exception e) {
LOG.warn("Unexpected exception", e);
}
}
};
snapInProcess.start();
}
logCount = 0;
}
// 如果是非事务请求(读操作)且toFlush为空
} else if (toFlush.isEmpty()) {
// 对于非事务请求,直接转交给下一个处理器
if (nextProcessor != null) {
nextProcessor.processRequest(si);
if (nextProcessor instanceof Flushable) {
((Flushable)nextProcessor).flush();
}
}
continue;
}
toFlush.add(si);
// 当提交的事务请求数量大于1000时进行磁盘刷入操作
if (toFlush.size() > 1000) {
flush(toFlush);
}
}
}
} catch (Throwable t) {
handleException(this.getName(), t);
running = false;
}
LOG.info("SyncRequestProcessor exited!");
}
private void flush(LinkedList<Request> toFlush)
throws IOException, RequestProcessorException
{
if (toFlush.isEmpty())
return;
// 事务日志刷到磁盘
zks.getZKDatabase().commit();
// 依次将事务请求转交给下一个处理器进行处理
while (!toFlush.isEmpty()) {
Request i = toFlush.remove();
if (nextProcessor != null) {
nextProcessor.processRequest(i);
}
}
if (nextProcessor != null && nextProcessor instanceof Flushable) {
((Flushable)nextProcessor).flush();
}
}
AckRequestProcessor Leader服务器特有处理器,主要负责在SyncRequestProcessor处理器完成事务日志后,向Proposal的投票收集器发送ACK反馈。
public void processRequest(Request request) {
QuorumPeer self = leader.self;
if(self != null)
// 向Leader反馈ACK
leader.processAck(self.getId(), request.zxid, null);
else
LOG.error("Null QuorumPeer");
}
CommitProcessor 事务提交处理器。对于非事务,直接交给下一个处理器。 而对于事务处理器,CommitProcessor处理器会等待集群内针对Proposal的投票直到Proposal提议可以被提交。
ToBeAppliedRequestProcessor 处理器中存在一个toBeApplied队列,用来存储那些已经被CommitProcessor 处理过可被提交的Proposal
FinalRequestProcessor 最后一个处理器,对客户端请求进行一些收尾操作,包括创建客户端请求的响应;针对事务请求,还会将事务应用到内存数据库中。
Follower
主要工作
- 处理非事务请求,将事务请求转交给Leader服务器
- 参与事务请求Proposal的投票
- 参与Leader选举投票
请求处理链

FollowerRequestProcessor 是Follower的第一个处理器,主要工作是识别出请求是否是事务请求,如果是事务请求则会将其转交给Leader服务器。
public void run() {
try {
while (!finished) {
// 阻塞出队请求,只有存在元素才会返回请求
Request request = queuedRequests.take();
if (LOG.isTraceEnabled()) {
ZooTrace.logRequest(LOG, ZooTrace.CLIENT_REQUEST_TRACE_MASK,
'F', request, "");
}
if (request == Request.requestOfDeath) {
break;
}
nextProcessor.processRequest(request);
switch (request.type) {
case OpCode.sync:
zks.pendingSyncs.add(request);
zks.getFollower().request(request);
break;
case OpCode.create:
case OpCode.delete:
case OpCode.setData:
case OpCode.setACL:
case OpCode.createSession:
case OpCode.closeSession:
case OpCode.multi:
// 事务请求转交给Leader服务器处理
zks.getFollower().request(request);
break;
}
}
} catch (Exception e) {
handleException(this.getName(), e);
}
LOG.info("FollowerRequestProcessor exited loop!");
}
public void processRequest(Request request) {
if (!finished) {
// 加入请求处理队列,等待线程循环处理
queuedRequests.add(request);
}
}
SendAckRequestProcessor 担任Follower服务器完成事务日志记录反馈的角色,在完成事务日志记录后,会向Leader服务器发送ACK消息以表明自身完成了事务日志的记录工作。
public void processRequest(Request si) {
if(si.type != OpCode.sync){
// 构造ACK消息
QuorumPacket qp = new QuorumPacket(Leader.ACK, si.hdr.getZxid(), null,
null);
try {
// 发送ACK消息给Leader服务器
learner.writePacket(qp, false);
} catch (IOException e) {
LOG.warn("Closing connection to leader, exception during packet send", e);
try {
if (!learner.sock.isClosed()) {
learner.sock.close();
}
} catch (IOException e1) {
// Nothing to do, we are shutting things down, so an exception here is irrelevant
LOG.debug("Ignoring error closing the connection", e1);
}
}
}
}
Observer

ObserverRequestProcessor 第一个处理器,主要工作是识别出请求是否是事务请求,如果是事务请求则会将其转交给Leader服务器。原理与Follower一样
相关文章
- 硅谷互联网公司的开发流程
开发流程包括这么几个阶段: OKR 的设立; 主项目及其子项目的确立; 每个子项目的生命周期; 主项目的生命周期; 收尾、维护、复盘。 第一点,OKR 的设立 所有项目的起始,都应该从 Ro
- RESTful-表述性状态转移风格
REST英文全拼:Representational State Transfer 面向资源编程 资源指的就是一类数据 产品表->就是产品资源 最重要的是如何表示一个资源 地址即
- 稳定性思考
产品功能线 0-1: 当系统从无到有的时候,首要考虑的是研发效率,功能快速迭代,满足快速增长的业务需求 1-10 系统已经搭建起来,此时考虑的是系统的稳定性。 可用性:1.隔离:区分出核心和非核心功能
- Supervisor守护队列发邮件
安装 CentOS: yum -y install supervisor Debien/Ubuntu适用:apt-get install supervisor 配置 修改主配置文件:vim /et
- 安装libsodium,让服务器支持chacha20等加密方式
用chacha20加密方式需要安装libsodium 注意:libsodium从1.0.15开始就废弃了aes-128-ctr yum install wget m2crypto git libsod
随机推荐
- 硅谷互联网公司的开发流程
开发流程包括这么几个阶段: OKR 的设立; 主项目及其子项目的确立; 每个子项目的生命周期; 主项目的生命周期; 收尾、维护、复盘。 第一点,OKR 的设立 所有项目的起始,都应该从 Ro
- RESTful-表述性状态转移风格
REST英文全拼:Representational State Transfer 面向资源编程 资源指的就是一类数据 产品表->就是产品资源 最重要的是如何表示一个资源 地址即
- 稳定性思考
产品功能线 0-1: 当系统从无到有的时候,首要考虑的是研发效率,功能快速迭代,满足快速增长的业务需求 1-10 系统已经搭建起来,此时考虑的是系统的稳定性。 可用性:1.隔离:区分出核心和非核心功能
- Supervisor守护队列发邮件
安装 CentOS: yum -y install supervisor Debien/Ubuntu适用:apt-get install supervisor 配置 修改主配置文件:vim /et
- 安装libsodium,让服务器支持chacha20等加密方式
用chacha20加密方式需要安装libsodium 注意:libsodium从1.0.15开始就废弃了aes-128-ctr yum install wget m2crypto git libsod